Attending a hackathon with Scala and Akka (Streams) on Microsoft Azure
While browsing through the unlimited supply of sh** posts on Facebook, I’ve stumbled upon an exciting invite to an “environmental hackathon” - named “Living with environmental changes / Življenje s podnebnimi spremembami” (event).
Online hackathon organised by a private company - Transformation Lighthouse - with collaboration with Slovenian Environment Agency - ARSO and Ministry of the Environment and Spatial Planning [MOP], plus few initiatives like Open Data Slovenia OPSI and business partners like Microsoft Slovenia, Oracle Slovenia and others.
At this point, you’re very likely already snoozed. 😴 And that is completely fine; so was I when I first read about the event.
It got me thinking, though,… Why would someone like to speed 48 hours working for the “government” during the weekend and lose a lot of sleep? 🤔 Well; my rationale is simple. By joining the event, I’ll get a rare glimpse into how government agencies - that usually sit on tons of incredibly valuable data - think about product development, the resources, data and insights that they can get out of it. It is the perfect environment to get the data about the environment - at the source (yeah I know I could just build my own weather station instead 🌤 ). In my current seek for interesting big-data and real-time data; could be the perfect quest.
Sold. I attended. ✅
Day zero: The research.
The day before the event I started browsing through all the available material that the organisers have compiled together while also looking for anything that is or could be turned into an API or data feed on all of the government sites. I found this lovely golden nugget on one of the pages.
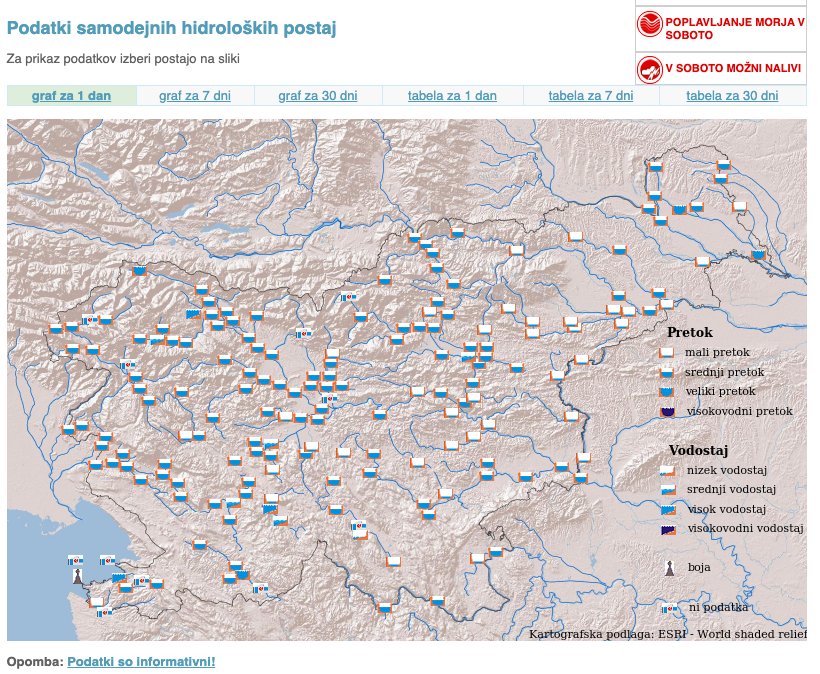
It is a “widget” that shows water levels and the flow of water in the country. You can see “buckets” that simulate if the flow is low, medium, or high. And after some more browsing, I found out that this data is available in XML format, and after that, I also found out that there is also historical data, in some cases 30+ years back.
And that got me thinking. What if I extract this “current” data and merge it with “historical” data; would then - in theory - be possible to predict the future with some degree of certainty? And that’s the idea. Bingo!💡
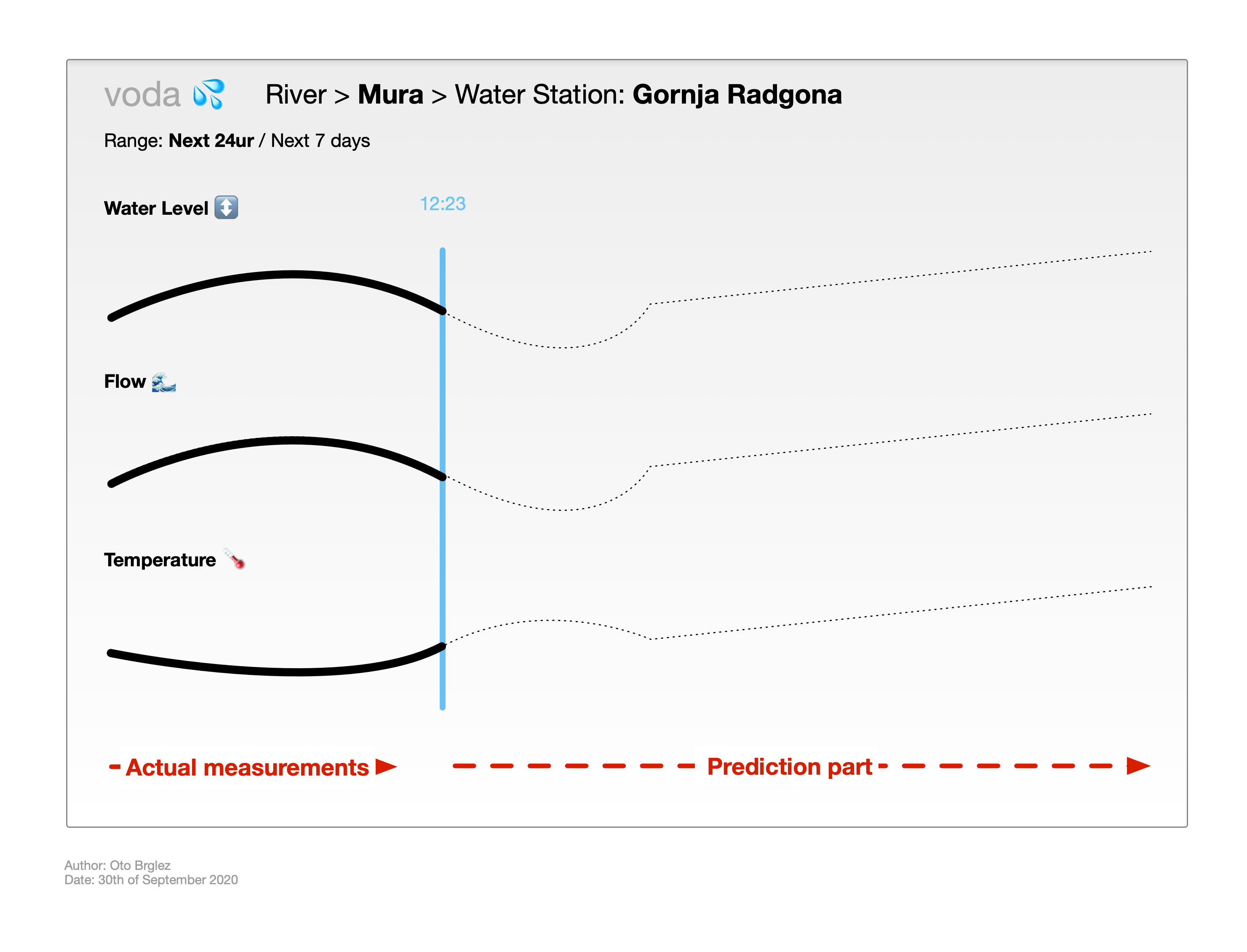
Day 1: Idea validation, PoC and Application
The following morning; the event took off. It was a traditional intro/marketing/ideas/make-world-a-better-place combo. The organisers and the agencies expressed their fields where they think the attendees could chip in. And provided a beneficial set of experts from various fields,…
We were given the following three subjects to chose from
- Impact of environmental changes
- Our relationship to natural resources - especially to water and drought
- Strategic game related to environmental changes
I’ve chosen the 2nd one - as I thought that the idea of understanding the water sources might somehow fit into that.
Problem numer one. With a bit of bad luck, I was put in a team where nobody showed up. Oops. 😅 I thought that this might ruin part of the fun but on second thought… 💡 If I work alone, I can move faster,… and I can focus on the core of my exploration. How to get the data, quickly and how to get to insight asap?
I spoke with organisers and asked them if it would be possible to work alone. To my surprise, they agreed, and I was ready. 🚀
The proof of concept
My idea was conceptually simple. Fetch the water data from government sites as quickly as possible, few requests per second with excellent parallelism… and turn that data into time-series. Make everything except the collection part “real-time”. And for the second part - archive - also use similar piping to fetch and process the historical data,… and hopefully, also ingest that into time-series or some other format.
My original idea was to scrape with Akka, and emit JSON to two separate Apache Kafka topics and then combine these two topics with ksqlDB query. After that, send the results of the streaming question to InfluxDB and visualise everything in Grafana of Grafana/ElasticSearch combo.
But then,… Like all great ideas. It evolved. Since one of the organisers of the event was Microsoft, I thought that I might look into Microsoft’s offering on Azure. So, what is managed alternative for Kafka / ksqlDB / InfluxDB on Azure?
Let’s ask the expert in the house. 💡
After a beautiful and insightful session with one of Microsoft’s Senior Cloud Architects, I got all the answers that I needed for this part. I just replaced the original components with Azure’s similar offering. And this is the result.
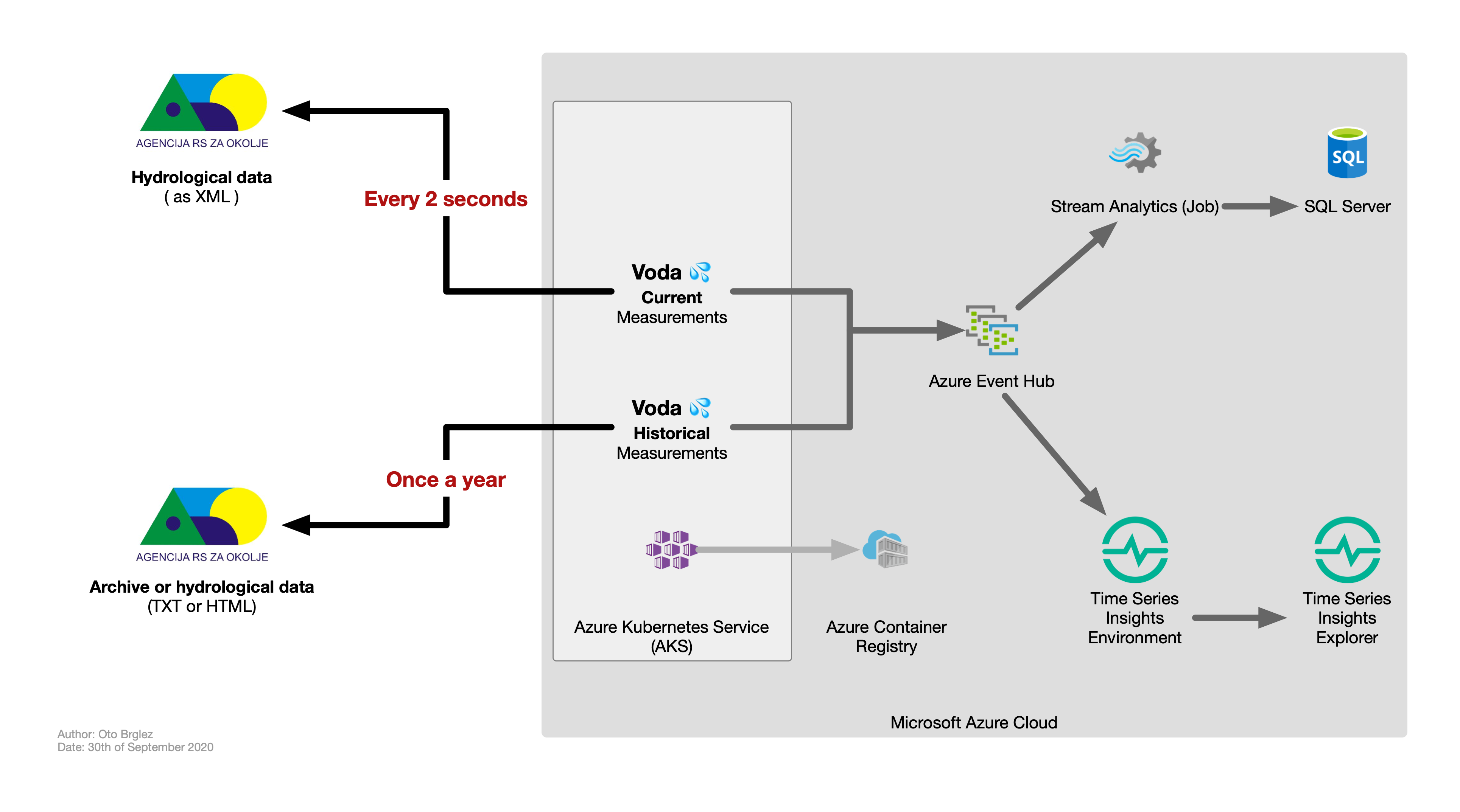
For those curious; what is used.
- Microsoft Azure Cloud as a magical platform,…
- Microsoft Azure Event Hubs, fully managed real-time ingestion service. That integrates seamlessly with existing Apache Kafka clients. Capable of streaming millions of events per second. Fun fact. It also comes with Schema Registry.
- Microsoft Azure Kubernetes Service (AKS) - Highly available, secure, and fully managed Kubernetes service. The commonplace to deploy and run your containerised application.
- Microsoft Azure Stream Analytics - Serverless real-time analytics, from the cloud to the edge. Think of this as fully managed “streaming analytics platform.”
- Microsoft Azure Container Registry - Azure’s answer to Docker Hub or GitHub container registry or … AWS’s or Google GCP’s. A place for storing your container images.
- Microsoft Time Series Insights (Environment and Explorer) - End-to-end IoT analytics platform to monitor, analyse, and visualise your industrial IoT data at scale. Think of it as your go-to IoT solution on Azure.
- Few other bits here and there,… but that’s mostly it.
The Scala / Akka application
Conceptually the application is split into two components; one long-running process that fetches water data every 5 seconds, transforms XML and pushes that into Azure Event Hub and another that is manually triggered - per demand - and fetches the whole archive in CSV and again pushes to the hub.
Collection of current measurements
Let’s look in the core or main one first,… First attempt at the collection,…
implicit val toEventData: StationReadingCurrent => EventData =
m => new EventData(m.asJson.noSpaces)
val hub = AzureEventBus.currentMeasurementsProducer
val collection = Source.tick(0.seconds, 5.seconds, Model.Tick)
// flow for requesting and parsing
.via(HydroData.currentFlow)
// Emitting the events to Azure Event Hub
.map(measurement => hub.send(measurement))
.runWith(Sink.ignore)
And parsing,…
def currentFlow(url: URL)
(implicit system: ActorSystem,
config: Configuration.Config) = {
import system.dispatcher
// Transformation of XML to "list" of "readings"
val toStationSeq: NodeSeq => Seq[StationReadingCurrent] = xml =>
(xml \\ "postaja").map { x =>
StationReadingCurrent(
sifra = x \@ "sifra", // Station key
reka = (x \ "reka").text, // River name
tempVode = (x \ "temp_vode").text.toDoubleOption // Temperature
// Others are emitted...
)
}
// Part that fetches and invokes transforamtion
def fetch: Future[Source[StationReadingCurrent, NotUsed]] =
Http().singleRequest(HttpRequest(uri = url))
.flatMap(r => Unmarshal(r).to[NodeSeq])
.map(toStationSeq)
.map(Source(_))
// Flow of ticks, that generates requests, ...
Flow[Model.Tick]
.mapAsyncUnordered(1)(_ => fetch)
.flatMapConcat(identity)
}
Now; since we live in a world where services go down, and in a world where it is irrational to bombard them with too much data….
We can make our collection a bit more resilient by wrapping the collection flow with RestartFlow.onFailuresWithBackoff. By doing this; we now made sure that if targeted service is down, our app will back-off, wait a bit and retry. If that fails 10 times; the whole app will come to a stop and terminate. Then ultimately - in our case - be restarted by Kubernetes.
The first enhancements look like this:
RestartFlow.onFailuresWithBackoff(5.seconds, 30.seconds, 0.3, 10) { () =>
Flow[Model.Tick]
.mapAsyncUnordered(1)(_ => fetch)
.flatMapConcat(identity)
}
And the second enhancement, since we use Akka Streams and Azure Hubs here, is to bulk these measurements together and emit them in batches. This can easily be achieved with the introduction of groupedWithin.
val collection = Source.tick(0.seconds, 5.seconds, Model.Tick)
.via(HydroData.currentFlow)
// This creates neet Seq of measurement batches
.groupedWithin(100, 100.milliseconds)
.map(measurements =>
// New "batch" is created and EventData "list" is attached to it.
hub.send(measurements.foldLeft(hub.createBatch()) { (batch, m) =>
batch.tryAdd(m)
batch
})
).runWith(Sink.ignore)
And since we don’t want to rely on the timestamp of the original data; we also override the “date”, with the date that the measurement was actually pushed to the hub with simple “copy”, like so
hub.send(measurements.foldLeft(hub.createBatch()) { (batch, m) =>
// Override of "date" with current date
batch.tryAdd(m.copy(datum = LocalDateTime.now))
batch
})
Collection of the archive data
The central part is very similar to the first application; just without the Source.tick.
implicit val toEventData: StationReadingHistorical => EventData =
m => new EventData(m.asJson.noSpaces)
val hub = AzureEventBus.historicalMeasurementsProducer
val f = VodaArchive.stationsSource
.via(VodaArchive.collectMetrics)
// Bigger batches here
.groupedWithin(5000, 1.second)
.map(measurements =>
hub.send(measurements.foldLeft(hub.createBatch()) { (batch, m) =>
batch.tryAdd(m)
batch
})
).runWith(Sink.ignore)
// Note: I could just write custom Sink for AzureEventBus, would be cleaner.
Since there is way more requests here that are emitted to fetch the data for every station for every year for last 20 years; throttling is introduced.
VodaArchive.buildRequests
// Throttling of requests before they are sent out.
.throttle(60, 1.second, 40, ThrottleMode.Shaping)
.mapAsync(4) { case (r, ctx) =>
Http().singleRequest(r)
.flatMap(Unmarshal(_).to[String])
.map(body => parseCSV(body)(r))
.map(_.map(_.map(concat(_)(ctx))))
}
.filterNot(_.isEmpty)
.mapConcat(identity) // Oops,...
.filterNot(_.isEmpty)
.map(_.getOrElse(throw new Exception("Only Row pass this point.")))
// Note: I could juse use FlowWithContext / SourceWithContext.fromTuples
Oh; and the Azure Event Hub producers look like this
object AzureEventBus {
def currentMeasurementsProducer(implicit config: Configuration.Config) =
new EventHubClientBuilder()
.connectionString(config.collecting.currentMeasurements.connectionString)
.buildProducerClient()
def historicalMeasurementsProducer(implicit config: Configuration.Config) =
new EventHubClientBuilder()
.connectionString(config.collecting.historicalMeasurements.connectionString)
.buildProducerClient()
}
And thats the core,… 😊
Docker, HELM and deployment
The two apps were bundled together into one application, and packeged together into Docker Image with help of sbt-native-packager. The Docker image was then pushed to Azure Container Registry (ACR).
object Boot {
def main(args: Array[String] = Array.empty): Unit = {
if (args.contains("--archive"))
ArchiveMain.main(args)
else
FetchMain.main(args)
}
}
Some Bash used for deployment,…
# Docker Image is built and pushed to Azure Container Registry.
# Then HELM is invoked to upgrade the thing.
sbt docker:publish && helm upgrade one chart/voda \
-f chart/voda/values.yaml --set image.tag=0.1.3
The thing is now deployed to Kubernetes,… … and collection runs smoothly. Win! 🏆
Sidenotes and tips:
-
Frinds don’t let friends use
kubectl! Use something like k9s for inspecting he state of your application on Kubernetes.
-
At this point. I should also state that using skaffold also came to my mind. However, this lovely error massage just made me not wanna spend more time on it. Perhaps in some other case…
$ skaffold init Projects set up to deploy with helm must be manually configured. See https://skaffold.dev/docs/pipeline-stages/deployers/helm/ for a detailed guide on setting your project up with skaffold.Althoug I didn’t use Skaffold here. I strongly suggest that you use it for rapid development; especially its
skaffold devcommand -
Telepresence - this is also one of those tools that you just have to use if you wanna move quickly around Kubernetes “ecosystem”. What it does is simple, it maps kuberntes ports and “hosts” to your local machine; and with that you can then your run your local app as it would be deployed inside Kubernetes. Very useful for debugging or just plain development.
Day 2. Wrap-up, finish and the results
After all the magical things were disigned, put together, deployed and once I’ve explored and configured everything that is sketched above… It was the second and final day of the hackathon. On this day I focused myself into wrapping up what I’ve started. I’ve polished the code a bit, made few changes here and there and made sure that collection and visualisation was working as expected.
Here, dear reader.
I give you a lovely real-time chart. On the left side you’ll see three measurement stations that are located on river Ljubljanica. Each of these stations measures temperature, flow and watter level.
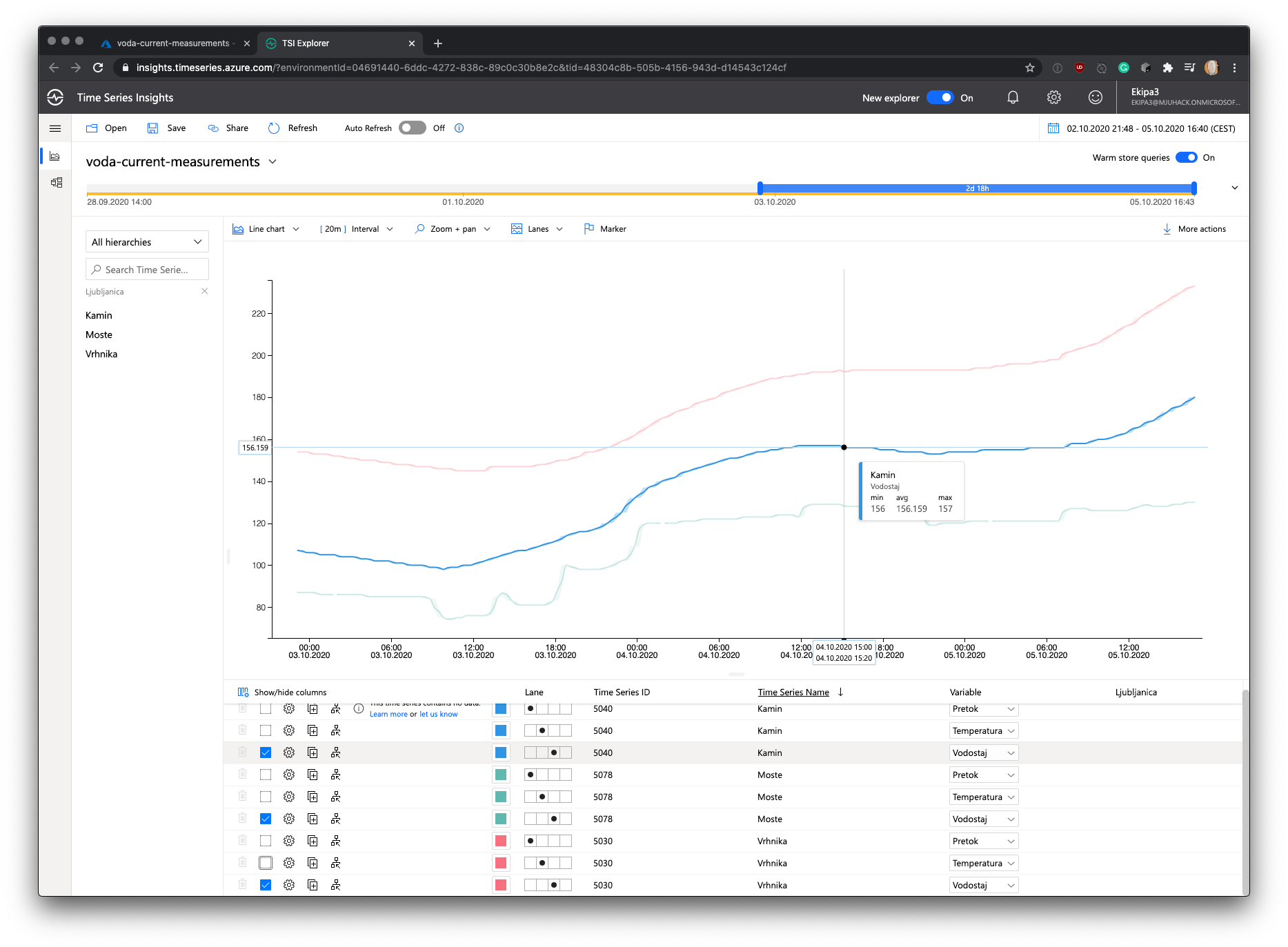
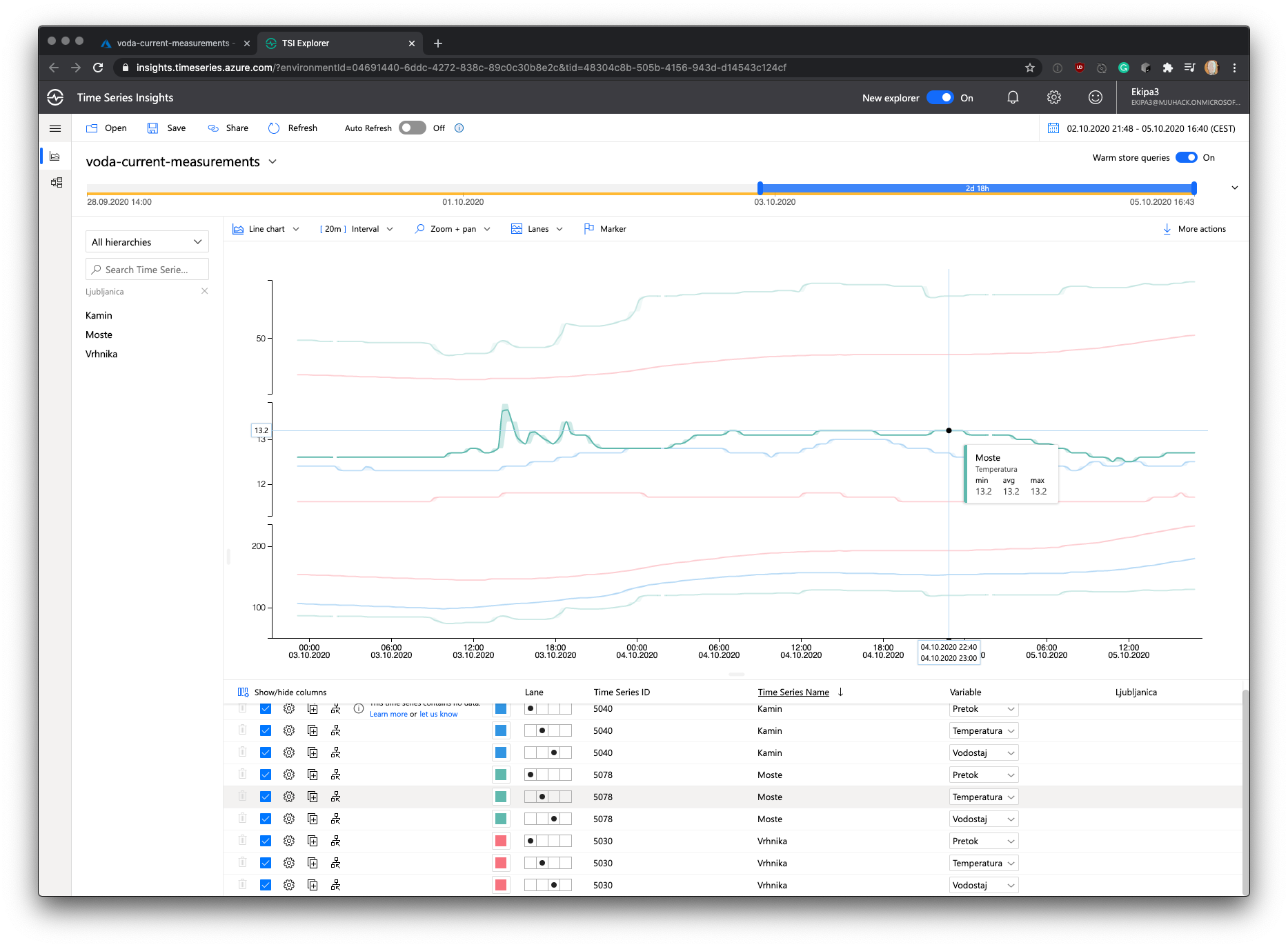
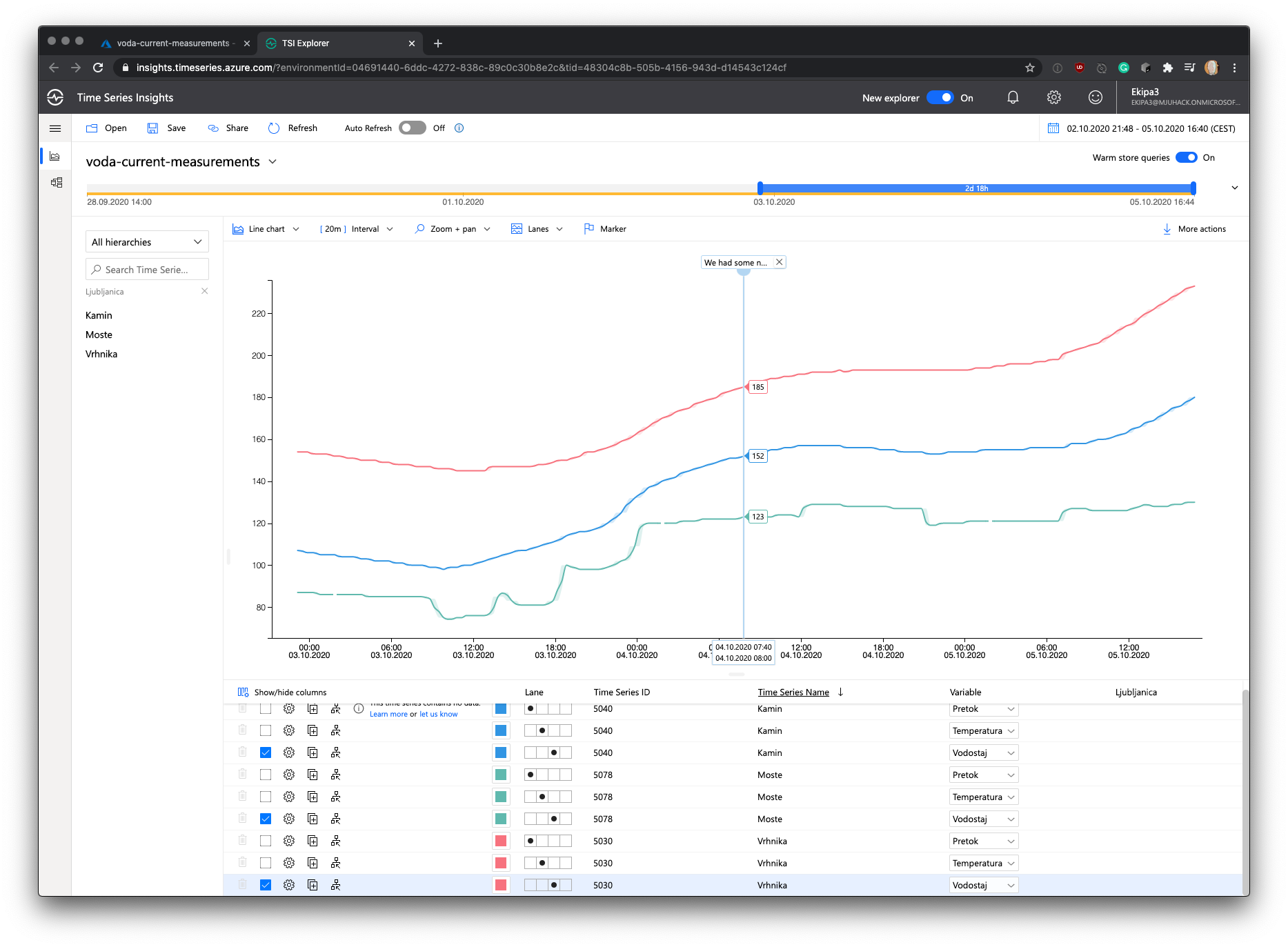
And some more stuff,..
I played around some more with streaming of events and transformation with Streaming Queries. So this also worked nicely; here a snippet if you want to transform JSON to “table rows” (SQL table) via Azure Streaming Analytics:
SELECT
*,
-- Extraction of date "parts" from timestamps
DATEPART (year, stream.datum) as c_year,
DATEPART (dayofyear, stream.datum) as c_dayofyear,
DATEPART (quarter, stream.datum) as c_quarter,
-- Creating a Geo-Point out of two floats (Coordinates)
CreatePoint(stream.geSirina, stream.geDolzina) as location
INTO
-- Destination Azure Event Hub (or Table)
[historicalmeasurements]
FROM
-- Azure Event Hub
[eh-archive] AS stream
Finish-line 🏁
I then filled out all the needed forms that organisers needed and wanted. Described my idea, solution and uniqness of it in great detail. Submitted everything… And waited… Waited some more… Fell asleep…
The results came in.
I didn’t make it. Sry. 😞 (🎻 <- this violin plays just for me)
Conclusion and summary
- You should attend a hackathon. Its great fun and you can meet a lot of great people. It will also force you to think about problems more, and it will also make you think more about what “can” you do within time constraints and what is out of reach or scope.
- Don’t expect to win just because you use fancy tech. Business people don’t care about it! They love shiny slide decks and magical videos that speak their language.
- Akka is incredible; the more you master it, the more will another tech around you look old and inadequate.
- Socialise. Although I went intentionally 100% solo in this endeavour and had support from organisers and partners, these things are social events. Perhaps the final idea might be as good if not better If I would collaborate with people more.
- Perhaps just draw a sketch or fake the data. (Yeah I hate that, just not me, I hate cheating!)
- Hackathons are mostly not what you can build; they are more about how and what you present.
- Research who is the target audience, what problem are you solving and if the jury appreciates the solution
- HALM, K8, etc… are over-kill unless you want to have fun and you don’t care.
- Data. Companies “hord” vast amount of incredibly valuable and unique data and don’t have the experts, tools or knowledge on how to monetise that data.
- If this kind of challenge is also your challenge; please let me know. I want to know more about it! ⚠️
- You are never too old to have fun! Life is short. Live it.
- We only have one planet, take care of it! 🌍
P.s.: What’s up with Azure, dude?
This is the first time I’ve used Microsoft Azure. I’ve been running and building things on AWS, GCP, DigitialOcean, Hetzner, Heroku, … own metal, etc. for ages now. But I never gave Microsoft a chance. Perhaps I’m one of the “old guys” now that has been around when Microsoft was waaaaay less open if not hostile to Open Source movement. So I always take Microsoft with caution…
I was very very impressed by Azure. Things felt very enterprise-ready, very coherent; the UI was clean; I felt “home”. I did struggle a bit with “resource groups” - I still think that they are entirely unnecessary, and I did have some challenges with finding the right logs, and reporting tools inside Azure. I was impressed by how well Streaming Analytics was packaged inside the SQL Server setup. As in - “look, just set it up here… its easy”. That was some nice up-sell from the Azure team.
Another plus; I’ve discovered this after the hackathon was; Azure DevOps Services. You can quite trivially setup GitHub Actions, and CI/CD pipeline with DevOps services. Making the deployment even more accessible and even more friendly. Sidenote. Microsoft didn’t put a cap on accounts that we used for the event. That gave me free hands to explore “everything” that I could get my hands on. I need to admit that perhaps if I had a bit more time, I would explore more of their IoT offering and machine learning suite. That s*** also looks extremely well-integrated and “easy”.
Fin.
P.s.s.: Give me some feedback if this kind or articles are interesting to you… or not? Below. 👇
P.s.s.s.: All the code from this hackathon are hosted on GitHub the project name is “voda”.
P.s.s.s.s: “Voda” stands for water in Slovenian 🇸🇮.